What We Do
We focuses on the analysis of “Deep Data”, large and information-rich data sets derived from many seemingly unrelated sources but linked across individuals to provide novel behavioral insights.
High dimensional discrete choice
A huge amount of economic data comes in the form of binary outcomes. Did a consumer purchase a product? Did a borrower default on a loan? These simple questions are surprisingly complicated to answer. A common approach is to build a statistical model with strong parametric assumptions. Our research agenda seeks to build more data adaptive methods that relax many of these assumptions. Under this umbrella we have two related projects. The first is a fully nonparametric multivariate choice model where we examine higher order correlations between choices. In a high dimensional setting and under sparsity, we can estimate correlation structure without making distributional assumptions.
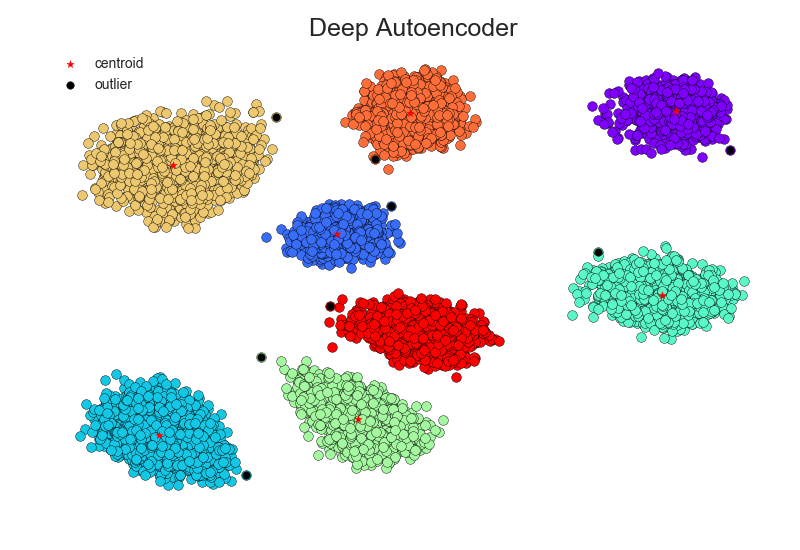 The second is a new method for choice estimation that operates under a latent factor assumption. We assume that an individual has preferences over bundles and those choices can be modeled by some nonlinear factor structure. To uncover these factors, we utilize a specific neural network architecture known as an Autoencoder. Using this approach, we can recover latent preferences and predict future choices.
The second is a new method for choice estimation that operates under a latent factor assumption. We assume that an individual has preferences over bundles and those choices can be modeled by some nonlinear factor structure. To uncover these factors, we utilize a specific neural network architecture known as an Autoencoder. Using this approach, we can recover latent preferences and predict future choices.
Inference with Neural Networks
 Deep learning has become a common buzzword in statistics and machine learning communities over the last few years. These algorithms have provided increasingly better prediction performance across a variety of tasks and disciplines. However, there is a gap in our understanding comes to confidence or prediction intervals for these estimates. This lack of uncertainty estimates has led to a great deal of mistrust surrounding these methods in the social sciences.
Deep learning has become a common buzzword in statistics and machine learning communities over the last few years. These algorithms have provided increasingly better prediction performance across a variety of tasks and disciplines. However, there is a gap in our understanding comes to confidence or prediction intervals for these estimates. This lack of uncertainty estimates has led to a great deal of mistrust surrounding these methods in the social sciences.
Our results show that neural networks and deep learning are not so different from other largely accepted nonparametric estimators, with a minor twist. Once we correct for this difference we can apply known results to construct confidence bands for functional estimates.
Survival modeling with Neural Networks
Predicting Mortality from Credit Scores
Survival analysis has a long history in Statistics and Economics. In these models we typically focus on analyzing data where the outcome variable is time until an event. Originally these models were applied in biostatistics to measure a patient’s survival duration after being diagnosed with one or more conditions. Later these models became very popular in Economics and can be used to understand the factors determining the duration of unemployment for a given worker, how long a borrower will take to repay a loan or whether a homeowner is likely to default on a mortgage. Over time these models have become increasingly flexible and our research focuses on the use of neural networks to develop a new class of fully non-parametric estimators.
In recent years, public health researchers have become aware that following the financial crisis individuals subject to major wealth shocks experience higher mortality rates. Based on this insight we are currently developing neural network survival models using a very large dataset of consumer credit data. We show that the data typically available in consumer credit reports such as the credit score can in fact substantially improve predictions of individual longevity.
Neural Networks and the Efficient Market Hypothesis
In 1988, Halbert White proposed the idea that while traditional linear models show no evidence of a failure of the efficient market hypothesis, it may be possible to uncover nonlinear patterns in stock return data by utilizing neural networks. White's original paper employed a very simple one layer neural network with 5 hidden neurons and unsurprisingly his results were negative. In recent decades however, many advances in machine learning have been made, especially with regards to neural networks and computational efficiency. White was limited by the computing power of the time and also didn't have access to more modern neural network architectures (for example Long Short Term Memory (LSTM) networks weren't invented until 1997).
 It has been well established since 1988 that neural networks have the potential to approximate any unknown mapping present in the data. Additionally, today we have the ability to fit much more complex neural network models than in 1988. For this reason we are investigating whether modern neural networks can uncover any nonlinear patterns that White was unable to detect.
It has been well established since 1988 that neural networks have the potential to approximate any unknown mapping present in the data. Additionally, today we have the ability to fit much more complex neural network models than in 1988. For this reason we are investigating whether modern neural networks can uncover any nonlinear patterns that White was unable to detect.
Quantile Neural Networks and Energy Forecasts
Quantile Regression is a generalization on the linear regression models. It allows for multiple prediction curves (instead of one in the linear regression model) thus providing more detailed distributional forecasts. We introducing a new nonparametric quantile model using neural networks which has substantial accuracy and computational speed gains over traditional methods. This model has a broad range of applications. We are currently exploring its predictive power in a model of household energy consumption with multiple dimensional input features.
Big Data, Machine Learning and Economic Policy
Machine Learning Approaches to Long Term Program Evaluation
In recent years there has been a great increase in the availability of microeconomic panel data over long periods of time, and as such the number of long term microeconomic studies has greatly increased. While panel data can be a very powerful tool for analyzing economic issues, using very long term panels can potentially introduce problems that standard panel data techniques don’t account for. While the typical assumptions used in panel data models usually hold for short run panels, it is generally not as clear if these assumptions hold in the long run. For example, a typical assumption is that individual effects don’t vary over time. While this may be reasonable for a panel spanning one year, it is less clear if this is reasonable to assume for a panel spanning 30 years, which may reduce the credibility of fixed effects estimation in this case. For this reason we are investigating the use of other approaches to the panel studies, such as factor models, whose use has generally been limited to macroeconomics. Comparing these methods with traditional methods will help us determine how credible fixed effect estimators really are.
How do local sales taxes influence prices and competition?
 While varying substantially from municipality to municipality and being remarkably complex in terms of how they are applied at the product level, local sales taxes have largely been overlooked in the economic literature. We explore sales tax complexity that comes from variance in rate of taxation as well as in the proportion of goods exempted from a given tax. To do this, we combine local sales tax data with grocery store scanner data of more than 166 million observations. We explore the relationship between tax complexity and prices, investigating whether grocery stores in areas with more complex taxes pass on the cost of compliance to consumers in the form of higher prices. We also explore the relationship between tax rate and complexity.
While varying substantially from municipality to municipality and being remarkably complex in terms of how they are applied at the product level, local sales taxes have largely been overlooked in the economic literature. We explore sales tax complexity that comes from variance in rate of taxation as well as in the proportion of goods exempted from a given tax. To do this, we combine local sales tax data with grocery store scanner data of more than 166 million observations. We explore the relationship between tax complexity and prices, investigating whether grocery stores in areas with more complex taxes pass on the cost of compliance to consumers in the form of higher prices. We also explore the relationship between tax rate and complexity.











